



hello,由于工作原因和服务器问题,好不容易找到了这个博客项目重新启用,很久没有发文写一些技术相关或是知识普及的文章了,2024的结束,迎来全新的2025deepseek在春节期间爆火。我也想蹭着热度还在通过自己个人了解还有网络上一些现有的信息资源给大家说下自己本地怎么部署deepseek。

一、本地部署的适用场景
本地部署适合以下情况:
电脑配置较高,有独立显卡:本地部署需要较强的硬件支持,尤其是GPU需求。
有私密数据需要处理,担心泄密:本地部署可以避免数据上传到云端,确保数据安全。
需要与本地工作交流结合:处理高频任务或复杂任务时,本地部署可以提供更高的灵活性和效率。
日常使用量大,调用 API 需要收费:本地部署可以节省 API 调用的费用。
想要在开源模型基础上做个性化定制:本地部署允许你对模型进行二次开发和定制。
总结:有钱有技术 + 怕泄密 → 本地部署 没钱没技术 + 图省事 → 直接使用网页/APP
部署前先了解下你需要的版本以及部署硬件需求:
其中最强悍的 671B 版本部署需要极高的硬件配置:64 核以上的服务器集群、512GB 以上的内存、300GB 以上的硬盘以及多节点分布式训练(如 8x A100/H100),还需高功率电源(1000W+)和散热系统。
不同模型版本对应的需求如下:
1、小型模型
DeepSeek-R1-1.5B
CPU:最低 4 核
内存:8GB+
硬盘:256GB+(模型文件约 1.5-2GB)
显卡:非必需(纯 CPU 推理)。
适用场景:本地测试,自己电脑上可以配合 Ollama 轻松跑起来。
预计费用:2000~5000,这个版本普通人是能够得着的。
2. 中型模型
DeepSeek-R1-7B
CPU:8 核+
内存:16GB+
硬盘:256GB+(模型文件约 4-5GB)
显卡:推荐 8GB+ 显存(如 RTX 3070/4060)。
适用场景:本地开发和测试,可以处理一些中等复杂度的自然语言处理任务,比如文本摘要、翻译、轻量级多轮对话系统等。
预计费用:5000~10000,这个版本普通人也行。
DeepSeek-R1-8B
CPU:8 核+
内存:16GB+
硬盘:256GB+(模型文件约 4-5GB)
显卡:推荐 8GB+ 显存(如 RTX 3070/4060)。
适用场景:适合需要更高精度的轻量级任务,比如代码生成、逻辑推理等。
预计费用:5000~10000,这个版本咬咬牙也能上。
3. 大型模型
DeepSeek-R1-14B
CPU:12 核+
内存:32GB+
硬盘:256GB+
显卡:16GB+ 显存(如 RTX 4090 或 A5000)。
适用场景:适合企业级复杂任务,比如长文本理解与生成。
预计费用:20000~30000,这个对 3000 工资的小编来说还是算了。
DeepSeek-R1-32B
CPU:16 核+
内存:64GB+
硬盘:256GB+
显卡:24GB+ 显存(如 A100 40GB 或双卡 RTX 3090)。
适用场景:适合高精度专业领域任务,比如多模态任务预处理。这些任务对硬件要求非常高,需要高端的 CPU 和显卡,适合预算充足的企业或研究机构使用。
预计费用:40000~100000,算了。
4. 超大型模型
DeepSeek-R1-70B
CPU:32 核+
内存:128GB+
硬盘:256GB+
显卡:多卡并行(如 2x A100 80GB 或 4x RTX 4090)。
适用场景:适合科研机构或大型企业进行高复杂度生成任务。
预计费用:400000+,这是老板考虑的,不该我去考虑。
DeepSeek-R1-671B
CPU:64 核+
内存:512GB+
硬盘:512GB+
显卡:多节点分布式训练(如 8x A100/H100)。
适用场景:适合超大规模 AI 研究或通用人工智能(AGI)探索。
预计费用:20000000+,这是投资人考虑的,不该我去考虑。
二、本地部署的基本步骤
1. LINUX环境部署:确保你的系统满足以下要求
操作系统:Linux(推荐 Ubuntu 20.04 或更高版本)或 Windows。
Python:3.8 或更高版本。
GPU:支持 CUDA 的 NVIDIA GPU(推荐16GB 显存以上)。
CUDA:11.2 或更高版本。
CUDNN:8.1 或更高版本。
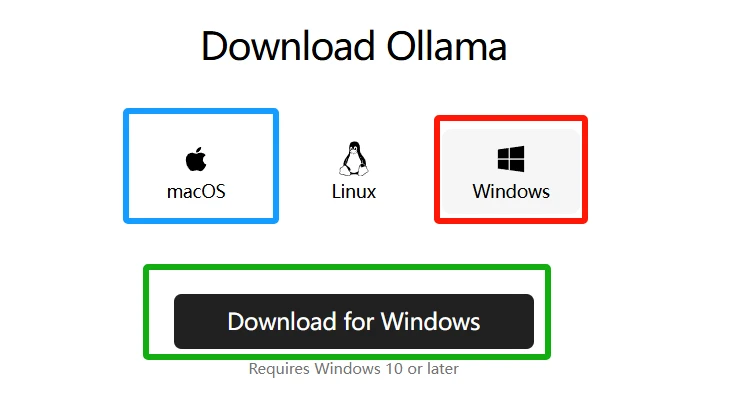
Linux择按照我编辑的跟着操作就行,Windows根据自己的电脑类型,选择不同版本。
苹果电脑选最左边(蓝色框),Windows系统选最右边(红色框),之后点击下载(绿色框)。
要在Ubuntu上通过Ollama安装和使用DeepSeek模型,可以按照以下步骤操作:
安装Ollama
1、使用命令安装Ollama
命令语句:curl -sSfL https://ollama.com/install.sh | sh
2、验证安装是否成功
安装完之后,您可以通过以下命令验证Ollama是否安装成功
命令语句:ollama --version根据自己需求下载需要模型 DeepSeek R1
同样在ollama的网站,在导航上找到【Models】,选择【deepseek-r1】模型,选择【1.5b】做测试,表示该模型有 15 亿个参数。
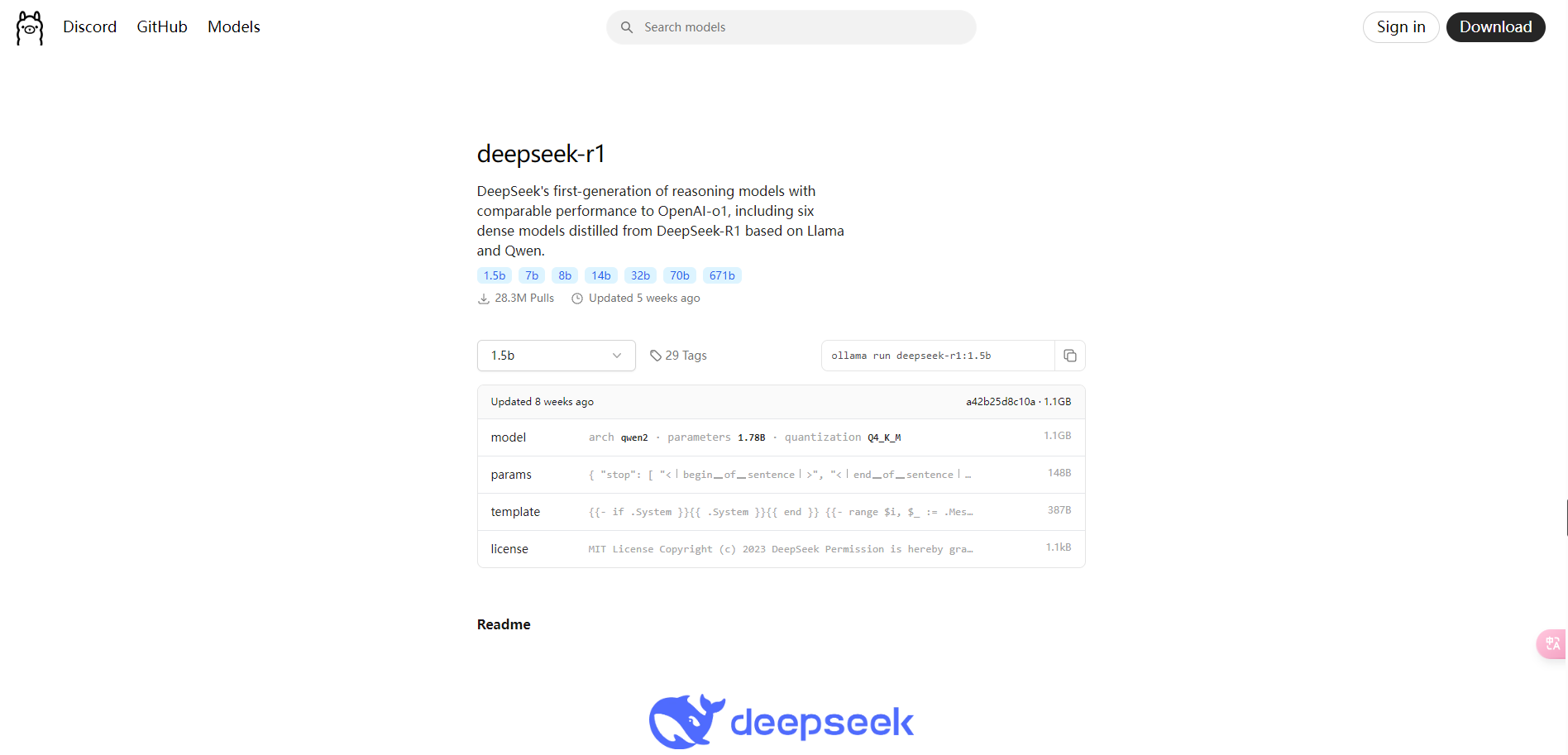
3、 下载并执行deepseek模型
ollama run deepseek-r1:1.5b
1.5b有1.1个G大小,需要下载一段时间,也可以把命令中的“run”换成“pull”,支持断点续传。
如果看到 success 字样也就说明模型下载完成了,执行命令ollama list可查看 ollama 目前所下载的模型列表。
4、 下载chatbox:
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。 地址:https://chatboxai.app/zh/
可以选择下载客户端到本地,或者直接在网页上访问,如果是本地大模型部署,选择前者。
5、 配置环境变量
在linux服务器端配置ollama服务。
5.1、修改/etc/systemd/system/ollama.service.d/override.conf文件
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
#ExecStart=/usr/local/bin/ollama serve #屏蔽掉此行
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/mysql8.0.30/bin:/home/gptt/myvenv/bin:/home/gptt/.local/bin:/home/gptt/anaconda3/bin:/home/gptt/anacond" #这个自动获取
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"5.2、重启ollama服务
systemctl daemon-reload
systemctl restart ollama.service
systemctl status ollama.service
查看端口状态,默认监听11434端口:
ss -tulnp

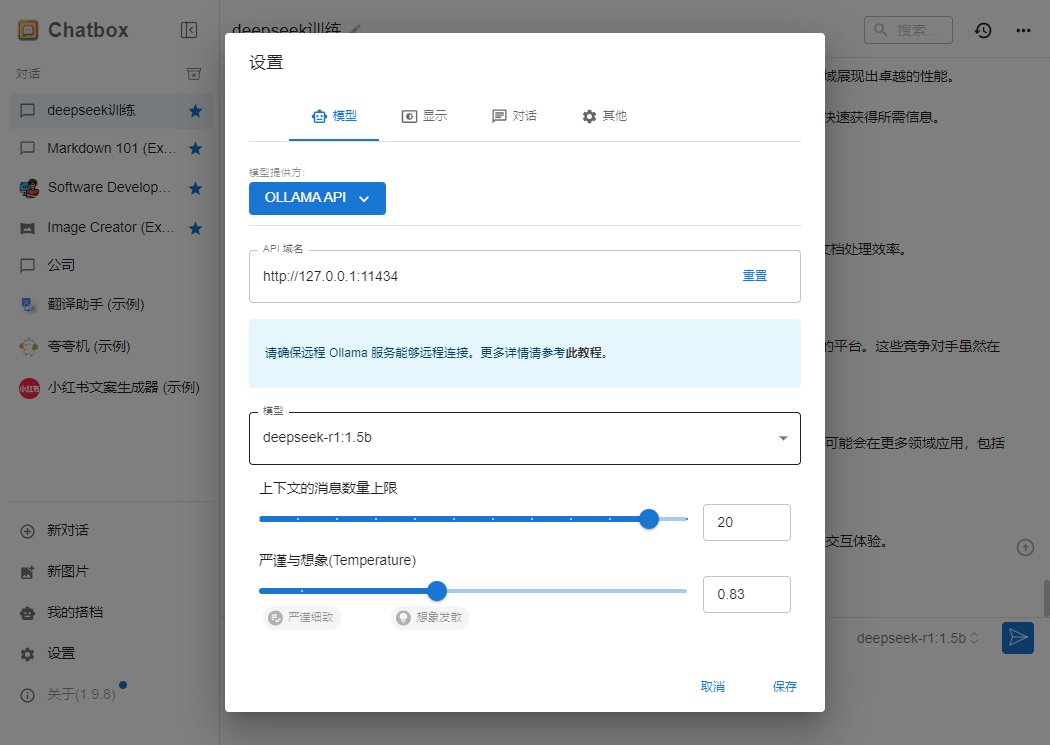
6、 配置chatbox
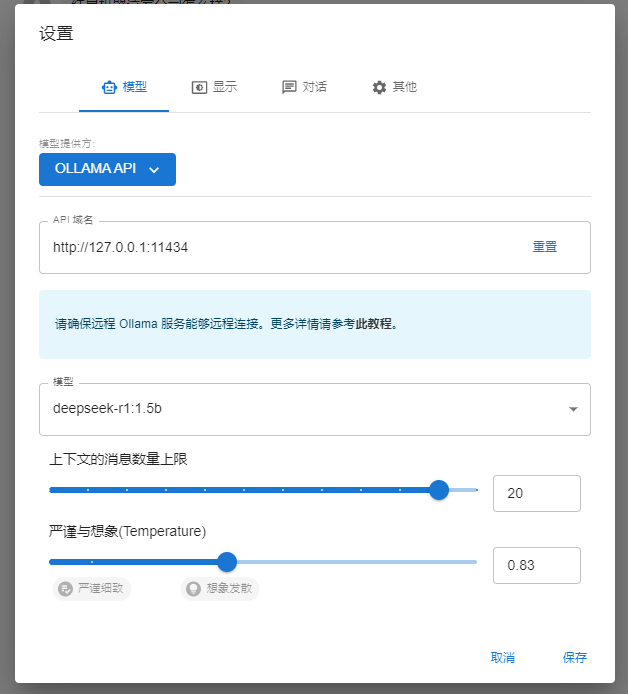
如果模型一开始不能显示,可以配置到第3步时先保存再设置就可以看到了,因为只有连接到本地大模型后才可以显示。
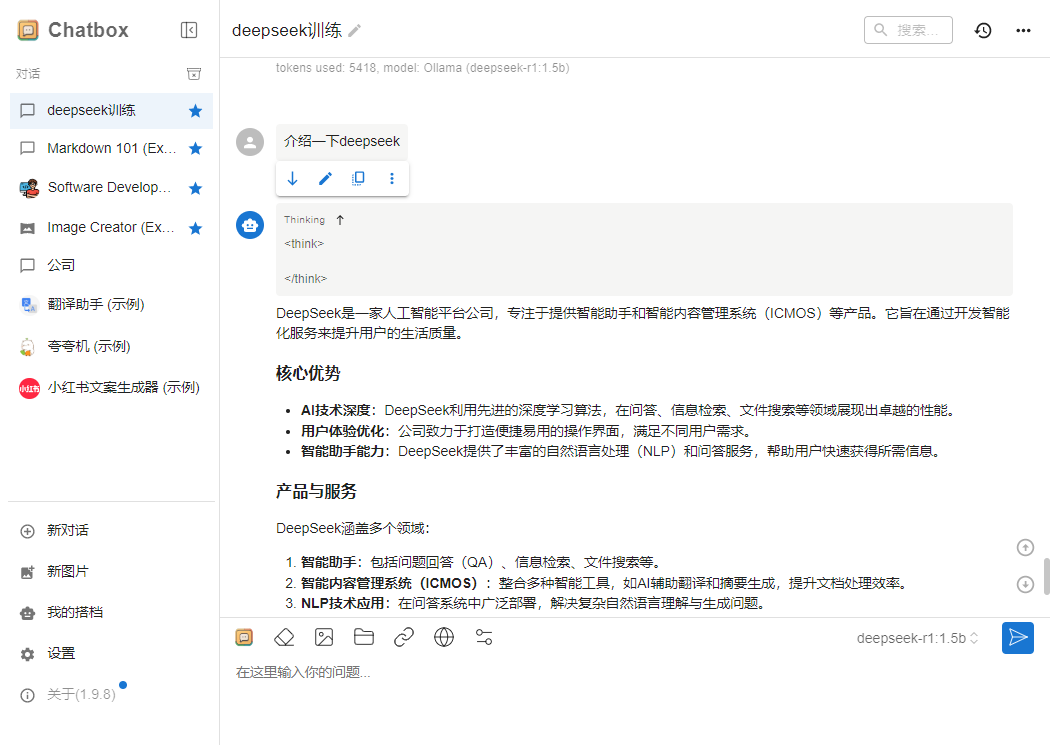
7、 开始对话
2.Windows系统环境部署:使用 Ollama 进行本地部署(简化版)
如果你觉得上述步骤过于复杂,可以使用 Ollama 来简化本地部署过程。Ollama 是一个用于管理 AI 模型的工具,特别适合初学者。
1、官网下载:ollama.com
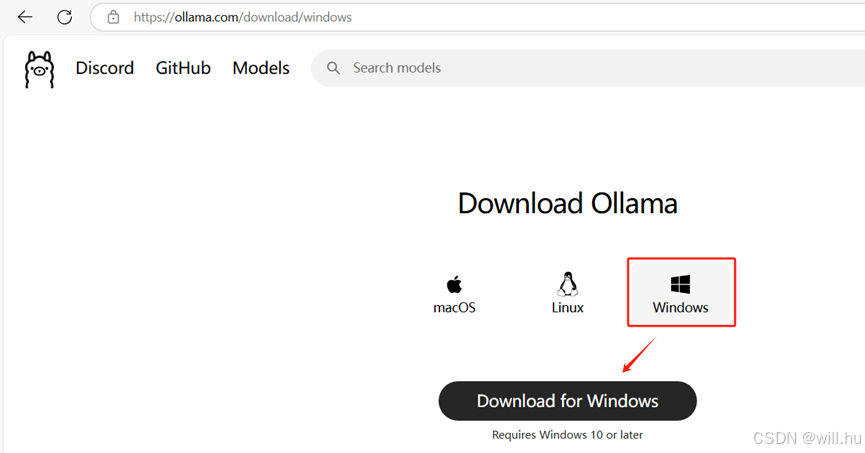
建议使用迅雷下载,IDM下载到后面,速度越来越慢!
打开下载好的文件,会自动安装并打开PowerShell运行。
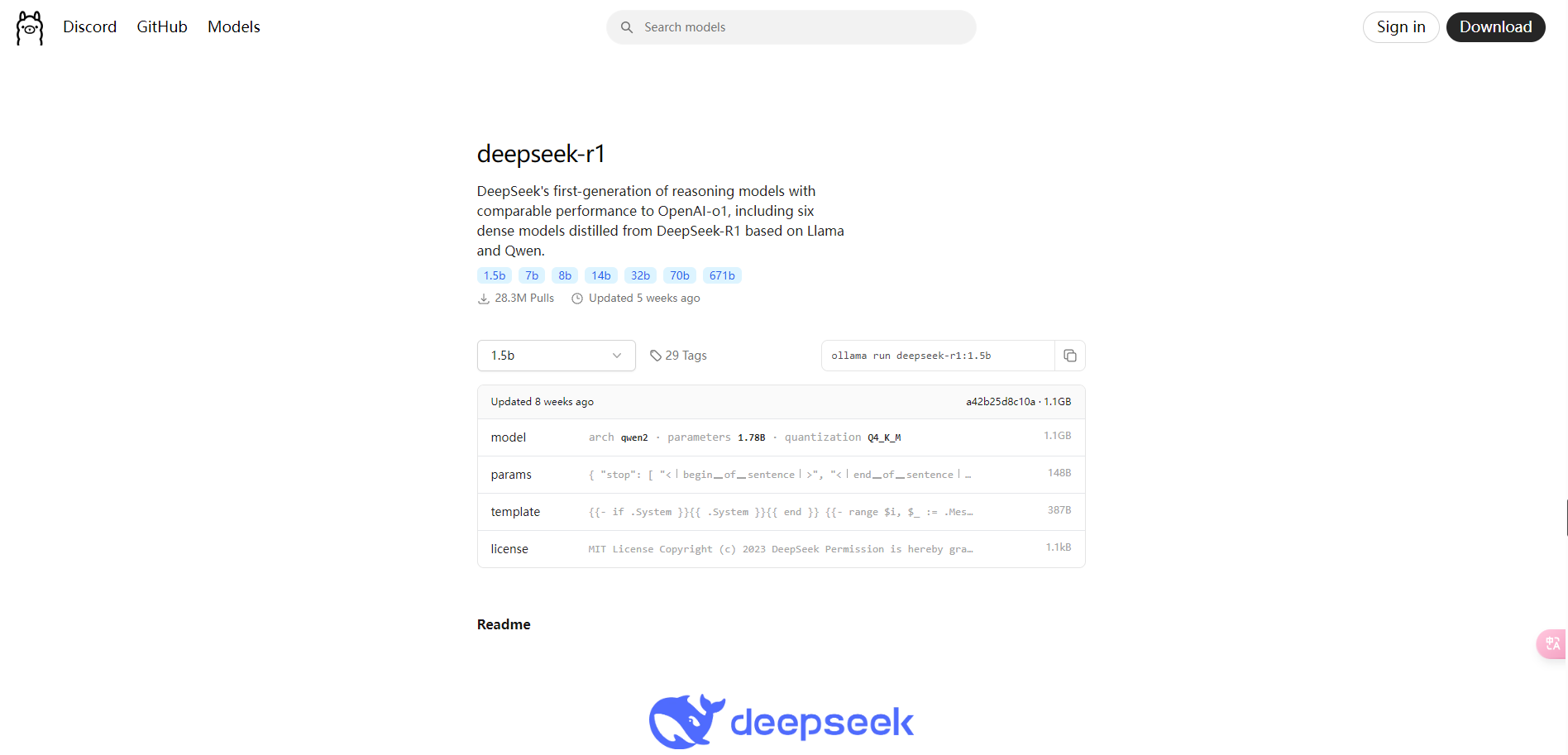
3、下载DeepSeek
在Ollama官网点击Models,选择deepseek-r1,选择版本如8b,复制版本右边的运行指令。
粘贴到powershell中运行:

耐心等待全部下载完成,出现“>>>Send a message”提示后,就可以开始对话了!
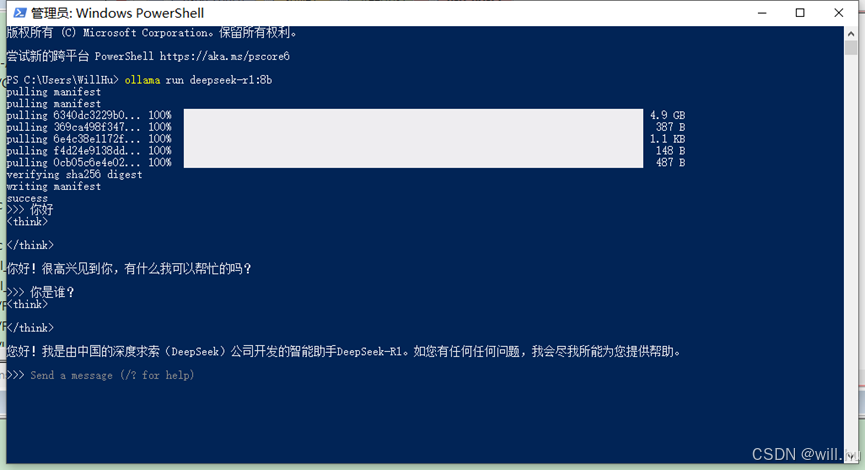
如果电脑配置比较低的话,响应是很慢的!
关闭PowerShell后,再打开 PowerShell并输入运行命令,可重新运行。
2.2移动其他盘储存
因为该软件和模型都是默认安装C盘,无法更改,我们的C盘正常来说,也很难承受几十个g的模型,所以我们就需要进行一定的修改。
1、移动ollama本身
首先我们需要更改ollama软件的储存位置,默认安装位置是
C:\Users\XX\AppData\Local\Programs\Ollama
我们只需要把整个ollama文件夹剪切到其他的盘即可
移动之后我们需要到环境变量中修改一下参数
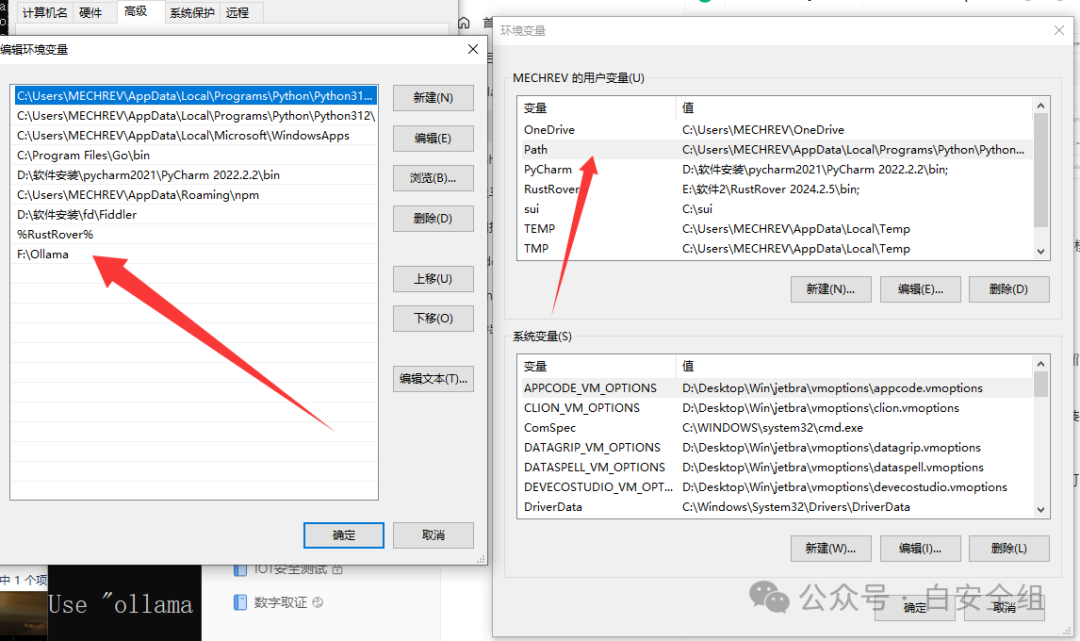
将你的ollama路径指定到你新的硬盘路径即可
打开cmd输入ollama正常出来即可。
2、移动模型
其实这里最关键的是大模型,这个我们可以用一个简单的方式来搞定。首先大模型的位置一般保存在
C:\Users\你的用户名\.ollama\models
这个目录下
我们移动就将.ollama整个剪切走,然后关键的一步就是软链接,也就是相当于建立了一个快捷方式留在原来的地方,但是实际本体被我们移动到了其他硬盘。
用cmd命令就可以简单实现。
mklink /J "C:\Users\你的用户名\.ollama" "D:\ollama\.ollama"

记住,要先删除原本的.ollama才可以创建软连接
最后通过ollama list查看大模型是否还在来检验移动后是否出错即可。
3、
运行我们需要指定好具体的模型名称和大小
ollama run deepseek-r1:14b
这样运行等待片刻即可
3.使用Chatbox对话
评论区